Кластеризация систем хранения данных с помощью NFS
LVEE 2018
Кластеризация СХД
Долгое время функция создания кластеров систем хранения данных относилось только к закрытым блочным системам. Популярность дешевых NAS и потребность в повышенной отказоустойчивости породило цклую плеяду кластерных объектных хранилищ со сложной системой управления и еще более сложными механизмами расчета производительности. В январе 2010 было обубликована спецификация протокола NFS v4.1 RFC 5661 которая позволят использовать несколько NAS как единое дисковое пространство.
NFS в классическом понимании состоит из серверного и клиентской частей, а тпкаже протоколов взаимодействия между ними. При работе с использованием NFS сервер скрывает реальную структуру дисковой и файловой системы, предоставляя унифицированную среду, таким образом обеспечивая кроссплатформенное общение.
Простая конфигурация NFS
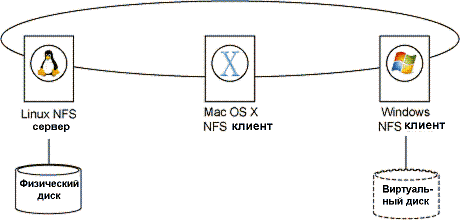
Рисунок 1 Конфигурация NFS v3
Операции по фактическому чтению/записи данных с/на дисковых или твердотельных накопителей осуществляет NFS-сервер. Вся работа с данными и метаданными возлагается на ресурсы сервера. Такой подход в реализации традиционно приводил к низким показателям производительности по операциям в секунду IOPS в случаях использования объектов большого размера или при случайных операциях с большим числом объектов. Использование точечных методов в решении таких вопросов (агрегация каналов, использование быстрых файловых систем, потоковая компрессия и дедупликация) хоть и поднимало производительность отдельно взятых NAS, но всё равно достижение уровня SAN было практически невозможно.
По крайней мере, так было раньше.
Версия NFS 4.1 включает в себя расширение инструкций в области паралелизации работы – Parallel NFS (pNFS), что даёт возможность избавиться от недостатков NFS-хранилища и обеспечить механизм повышения скорости передачи данных (за счёт обеспечения распараллеливания операций ввода/вывода).
При работе с pNFS клиенты, как и раньше, имеют доступ к файловой системе сервера, однако рабочие потоки обработки метаданных и данных разделены. Сервер метаданных pNFS обеспечивает выполнение фазы инициализации соединения, после чего обемен данным осуществляется между клиентом и сервером NFS. Конфигурация pNFS показана на рисунке 2
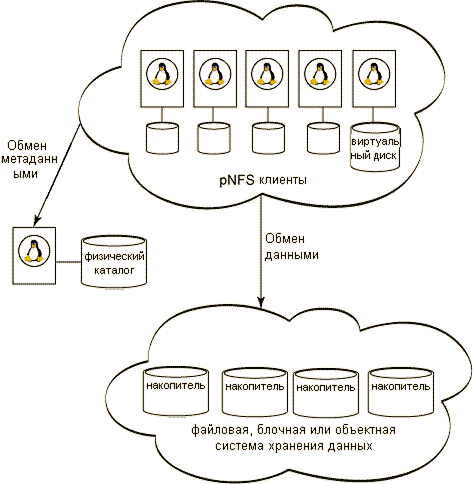
Рисунок 2. Концепция организации pNFS
Задачами сервера метаданных является экспорт файловой системы, хранение и поддержание каноничных метаданных. Клиент новой версии обеспечивает монтирование конечной файловой системы на основании данных pNFS сервера и обеспечивает непосредственное взаимодействие в работе с данными с NFS серверами.
Сервер pNFS не участвует в транзакциях по передаче данных, что повышает производительность.
Такой подход в работе pNFS сохраняет все удобства и преимущества NFS, добавляя к ним производительность и масштабируемость.
pNFS в деталях
Протокол pNFS передает метаданные о объектах, в рамках единой разметки (layout), между сервером pNFS и клиентским узлом. layout описывает, как объект распределен в системе хранения данных: например, как он поделен между несколькими носителями; также в layout содержатся атрибуты файла (права доступа и т.д.). Все метаданные сохраняются в файлах разметки и хранится на сервере pNFS, а система хранения данных занимается только вводом/выводом информации.
Протокол доступа к системе хранения данных (Storage access protocol) регулирует работу клиента с системой хранения данных. Каждый протокол доступа к системе хранения данных работает с индивидуальным layout.
Протокол управления (Control protocol) служит для синхронизации между сервером метаданных и сервером данных. Синхронизация — например, реорганизация файлов на носителях— скрыта от клиентов.
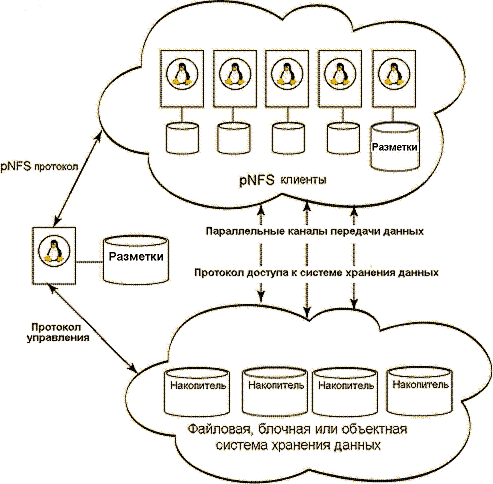
Рисунок 3. Триада протоколов pNFS.
Итак, процесс доступа клиента к данным выглядит так:
- Клиент запрашивает разметку файла, с которым предстоит работать.
- Клиент получает права доступа путем открытия файла на сервере метаданных.
- Авторизовавшись и получив разметку файла, клиент может получать информацию непосредственно с сервера данных. Работа осуществляется в соответствии с протоколом доступа, требуемым для этого типа носителя (подробнее ниже).
- Если клиент изменяет файл, клиентская копия разметки изменяется необходимым образом, после чего передается на сервер метаданных.
- Когда клиент больше не нуждается в файле, он записывает оставшиеся изменения, передает свою копию разметки обратно на сервер метаданных и закрывает файл.
Более подробно операция чтения (READ) – это серия следующих операций протокола:
- Клиент посылает запрос LOOKUP+OPEN на сервер pNFS. Сервер возвращает дескриптор файла (file handle) и информацию о состоянии файла.
- Клиент запрашивает с сервера разметку с помощью команды LAYOUTGET. Сервер возвращает разметку файла.
- Клиент посылает запрос READ на устройства хранения, которые инициируют множество параллельных операций READ.
- Когда клиент заканчивает чтение, он посылает команду LAYOUTRETURN.
- Если клиентская копия разметки становится неактуальной (из-за изменения серверной разметки каким-либо другим, выполняющимся параллельно действием), сервер посылает команду CB_LAYOUTRECALL, сообщая, что разметка уже не действительна и ее надо обновить.
Операция Write выглядит так же, за исключением того, что клиент шлет команду LAYOUTCOMMIT перед командой LAYOUTRETURN, чтобы «опубликовать» свои изменения файла на сервере pNFS.
Разметки могут кэшироваться на каждом клиенте, что еще больше повышает скорость работы. Также клиент может при желании удалять свою копию разметки полученной с сервера, если она больше не используется. Также сервер позволяет ограничивать в разметке размер записываемых данных, чтобы, например, не использовать дисковые квоты или уменьшить издержки на выделение ресурсов.
Для того чтобы данные в кэше оставались актуальными, сервер метаданных отзывает устаревшие разметки. Все затронутые отзывом клиенты должны приостановить работу с данными и, либо обновить свою версию разметки, либо продолжить работу через обыкновенную NFS. Сервер обязательно делает отзыв разметки перед началом административной работы с файлом (например, миграции или изменения распределения файла по системам хранения).
Независимо от типа разметки pNFS использует для обращения к серверам общую схему. Вместо имени хоста или тома накопителя обращение к серверам происходит по уникальным идентификаторам. Этому идентификатору ставится в соответствие зависящая от конкретного протокола доступа ссылка на сервер.
Какой из этих методов хранения лучше? Ответ индивидуален и зависит от размера бюджета, масштаба системы, требуемой скорости, простоты работы и других факторов.
Текущее состояние pNFS
Нативная поддержка протокола на уровне ядра доступна с версий
2.6.37, поддержка всего функционала полностью реализована в ветке 3.1.
Мейнтейнером развития является коммерческая организация panasas, активная часть сообщества – 118 аккаунтов.
Основная ветка развития протокола 4.1 завершена в 2010 году.
С 2014 и по настоящее время идёт стандартизация (формально завершена в 2016) и развитие ветки 4.2.
Ссылки
- https://www.snia.org/sites/default/files/NFS_4.2_Final.pdf
- http://linux-nfs.org
- https://www.ibm.com/developerworks/ru/library/l-pnfs
- https://tools.ietf.org/html/rfc7862
- https://tools.ietf.org/html/rfc5661
Abstract licensed under Creative Commons Attribution-ShareAlike 3.0 license
Back



























