Создание СХД с томами «тонкой» настройки на базе дистрибутива Linux
LVEE 2019
Общее описание, модель хранения данных, основные переменные, пример расчета для СХД с томами «тонкой» настройки на базе дистрибутива Linux.
Тома с «тонкой» настройкой 1 или «подготовкой» (thin provisioning) это виртуальная абстракция устройства хранения данных с заранее определенными параметрами, но имеющим изначально относительно небольшой размер и поддерживающим технологию динамического распределения блоков для хранения данных из общего хранилища.
Они широко применяются в системах хранения данных (СХД) и виртуализации для эффективного использования доступного дискового пространства между пользователями ресурсов с учетом их потребностей.
Данное решение базируется на концепции избыточного распределения, и разработанных на ее основе технологий и механизмов для создания СХД с использованием виртуальной абстракции устройства (файл или блочное устройство).
При этом, формат файла, как виртуальной абстракции устройства хранения данных, содержит в себе полную структуру и содержимое сходную с форматом жёсткого диска, а его размер может быть фиксированным (определено максимальное его значение) или динамическим (размер файла изменяется по мере его заполнения данными до максимального заданного значения).
Если в качестве виртуальной абстракции используется блочное устройство, то, может использоваться одноуровневая или двухуровневая модель хранения данных.
При одноуровневой модели создается виртуальное блочное устройство большой емкости, при начальной инициализации содержащий небольшое количество блоков для хранения данных, дополнительные блоки добавляются из хранилища по мере необходимости (максимальное количество блоков которое может быт добавлено в устройство определяется переменной).
При двухуровневой модели (рисунок 1) создаются две виртуальные абстракции: общий пул хранения данных и виртуальные логические тома для пользователей.
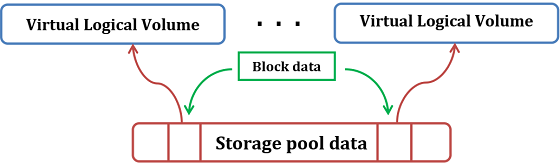
Рисунок 1. Двухуровневая модель.
Распределением блоков для хранения данных из общего пула между виртуальными логическими томами управляет программа-менеджер. В случае необходимости новые блоки для хранения данных добавляются в общий пул, и в автоматическом режиме распределяются между виртуальными логическими томами, исключая необходимость проводить дополнительные манипуляции с ними (например, изменения размера файловой системы). При этом реальный размер каждого виртуального логического томам может превосходить суммарный объем общего пула хранения данных.
В ядре Linux абстракции виртуальных блочных устройств реализуются с помощью модуля «Device mapper» 2, а начиная с версии ядра 3.2 в него добавлена поддержка динамического выделения места в хранилище данных (thin provisioning) с возможностью реализации двухуровневой модели хранения данных.
При создании СХД с использование томов с «тонкой» настройкой (thin provisioning) 3 на базе дистрибутива Linux необходимо учитывать версию ядра, возможности поддержки требуемого функционала с помощью дополнительных модулей, и расширения общего пула хранения данных с учетом возрастающих потребностей.
Типовая структурная схема включает в себя два основных компонента: пул устройств (или том с “тонкой” настройкой thin pool) объединяющий вместе том метаданных (meta pool) и том данных (data pool) и виртуальные тома (virtual volume) для пространства пользователя. В случае использования менеджера логических томов LVM2 4, создание пулов томов с “тонкой” настройкой (thin pool) осуществляется в пределах одной Volume Group (VG) (рисунок 2).
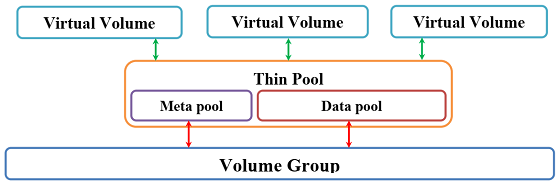
Рисунок 2. Типовая структурная схема СХД с томами “тонкой” настройки
При этом несмотря на это ограничение использование LVM2 более предпочтительно так как позволяет использовать дополнительные возможности:
- подключение внешнего хранилища, доступного в режиме только для чтения в качестве основы для создания типовых LVM-разделов, при котором все обращения на чтение не изменённых данных прозрачно транслируются к базовому эталонному хранилищу, а все изменённые или новые данные обрабатываются в отдельном слое в режиме чтения-записи;
- поддержку динамической агрегации метаданных при помощи демона lvmetad;
- поддержку технологии LVM Cache для общих пулов хранения данных;
- работы со снапшотами.
Перед созданием СХД необходимо определить параметры каждого виртуального тома, их суммарный общий объем (переменная $data_dev_size_max), текущий доступный объем для тома данных (переменная $data_dev_size), возможность использования дополнительных накопителей для тома с метаданными (включая возможность резервирования), выбрать программу-менеджер для управления и используя формулы приведенные ниже определить значения ключевых переменных, при этом, для утилиты dmsetup модуля «Device mapper» все значения указываются в количестве блоков, для LVM2 в байтах или других представлениях единиц измерений.
Размер виртуальных томов (virtual volume)
Размер виртуальных томов (virtual volume) для пространства пользователей определяет администратор на основании технического задания или иных предпочтений, однако, при этом суммарный размер виртуальных томов не должен превышать предельно допустимые физические параметры системы хранения данных в целом, в случае необходимости должна быть реализована возможность их расширения с учетом возрастающих потребностей.
Размер фрагмента выделения (chunk size)
$data_block_size=$dev_min_block_size * $count_block, где
$dev_min_block_size – минимальный размер блока данных на устройстве, как правило, это значение равно 512 байт.
$count_block – количество блоков данных которые можно использовать при раздаче, как правило от 128 до 2097152 для обычных томов данных, для сложной структуры 128, для снапшотов от 8 до 1048576.
Размер тома с метаданными
$metadata_dev_size = 48 * $data_dev_size_max / $data_block_size, где
$data_dev_size_max – полный размер тома данных;
$data_block_size – размер фрагмента выделения.
При этом необходимо учитывать, что размер тома для хранения метаданных не может быть меньше 2Мб, и больше 16Гб, рекомендуемое значение по умолчанию 1Гб. Если по итогам расчетов размер тома для хранения метаданных превышает значение 16Гб, рекомендуется создавать несколько пулов хранения данных.
К размещению метаданных тонких томов стоит относится аккуратно, так как, если данное пространство будет исчерпано, то пул будет выдавать ошибки ввода-вывода до тех пор, пока пул не будет переведен в автономный режим, и не будет выполнено восстановление для устранения потенциальных несоответствий. Поэтому, рекомендуется для пространства метаданных использовать отдельное выделенное устройство или несколько устройств с возможностью резервирования (например, объединить их в raid 1), а для повышения производительности использовать твердотельные накопители.
Определение значения переменной $low_water_mark
$low_water_mark = $count_block_sign_error * $data_block_size,
$count_block_sign_error — значение количества свободных блоков в пуле данных при достижении которого выдать сигнал об исчерпании места;
$data_block_size — текущее значение размера блока распределения.
Значение переменной $count_block_sign_error определяется системным администратором исходя из размера пула и критичности его оперативного расширения. Значение переменной $low_water_mark используется для генерации однократного сигнала предупреждения при достижении низкого уровня свободного места в пуле хранения данных.
После выполнения расчета и анализа результатов, если необходимо провести корректировку значения $data_dev_size, определить устройства для хранения данных и метаданных и выполнить первичную сборку и настройку СХД.
Пример расчета:
Условие:
Необходимо создать хранилище данных для 100 виртуальных машин с томами размером по 50GB для каждой, при наличии физического дискового пространства в 200GB и одного накопителя sdd емкостью 128GB.
- Определим значение переменной $data_dev_size_max:
$data_dev_size_max=100*50*1073741824=5 368 709 120 000 байт - Определим значение переменной $data_dev_size, установив его значение в 98% от максимально возможного (рекомендовано):
$data_dev_size=(200*1073741824)*0.98=210 453 397 504 байт - Определим размер фрагмента выделения значением по умолчанию в 128 блоков по 512 байт:
$data_block_size = 128 * 512 =65 536 байт - Определим размер тома для хранения метаданных:
$metadata_dev_size = 48 * 5 368 709 120 000/65 536 = 3 932 160 000 байт или примерно 3,67GB - Повторим предыдущие два вычисления, изменив исходные данные.
Определим размер фрагмента выделения значением в 256 блоков по 512 байт:
$data_block_size = 256 * 512 = 131 072 байт
Определим размер тома для хранения метаданных:
$metadata_dev_size = 48 * 5 368 709 120 000/131 072 = 1 966 080 000 байт или примерно 1,83GB
Как видно, чем больше размер фрагмента выделения, тем меньше будет необходим том для хранения метаданных. - Определим значения переменной $low_water_mark, установив, ее значение равной 1024 блока:
$low_water_mark = 1024 * 131 072 = 134 217 728 байт или примерно 128МБ
Если это значение критично, то может его увеличить, например до 65 536 блоков:
$low_water_mark = 65 536 * 131 072 = 8 589 934 592 байт или примерно 8ГБ. - Сопоставим полученные результаты с исходными данными и выберем оптимальный вариант для создания пула с “тонкой” настройкой.
Ссылки
1 Thin provisioning Wikipedia «Thin provisioning»
2 Device mapper Device mapper
3 Documentation kernel.org Thin provisioning
Abstract licensed under Creative Commons Attribution-ShareAlike 3.0 license
Назад



























