Introduction to distributed file systems. OrangeFS experience
LVEE Winter 2013
Preface
Why one needs a non-local file system? Goals may vary, but usually they arise from the need of:
- a large data storage;
- a high performance data storage;
- redundant and highly available solutions.
There are dozens of solutions available1, and many of them are open source. But how to choose one you need? There is a lot of ambiguity and vagueness in this field, but let’s try to sort it out.
Focusing on open source solutions, one can see they are usually sufficient for any needs and are used on the most high performance systems from Top-5002 list, especially in the top 50 of them.
Species of distributed file systems
Even the term “distributed” is ambiguous itself. It may mean all kinds of file systems running on more than a single host (sense used in a title of this article), but it also means a subset of this common sense discussed below. It should be understandable, that there is no canonical definitions in this field, so terminology found in different sources may vary.
Every non-local file system (except for few exotic cases) may be roughly related to one of the following classes:
- network file systems;
- clustered file systems;
- distributed file systems.
Of course, there is a large intersection between these sets. See fig.1 for details.
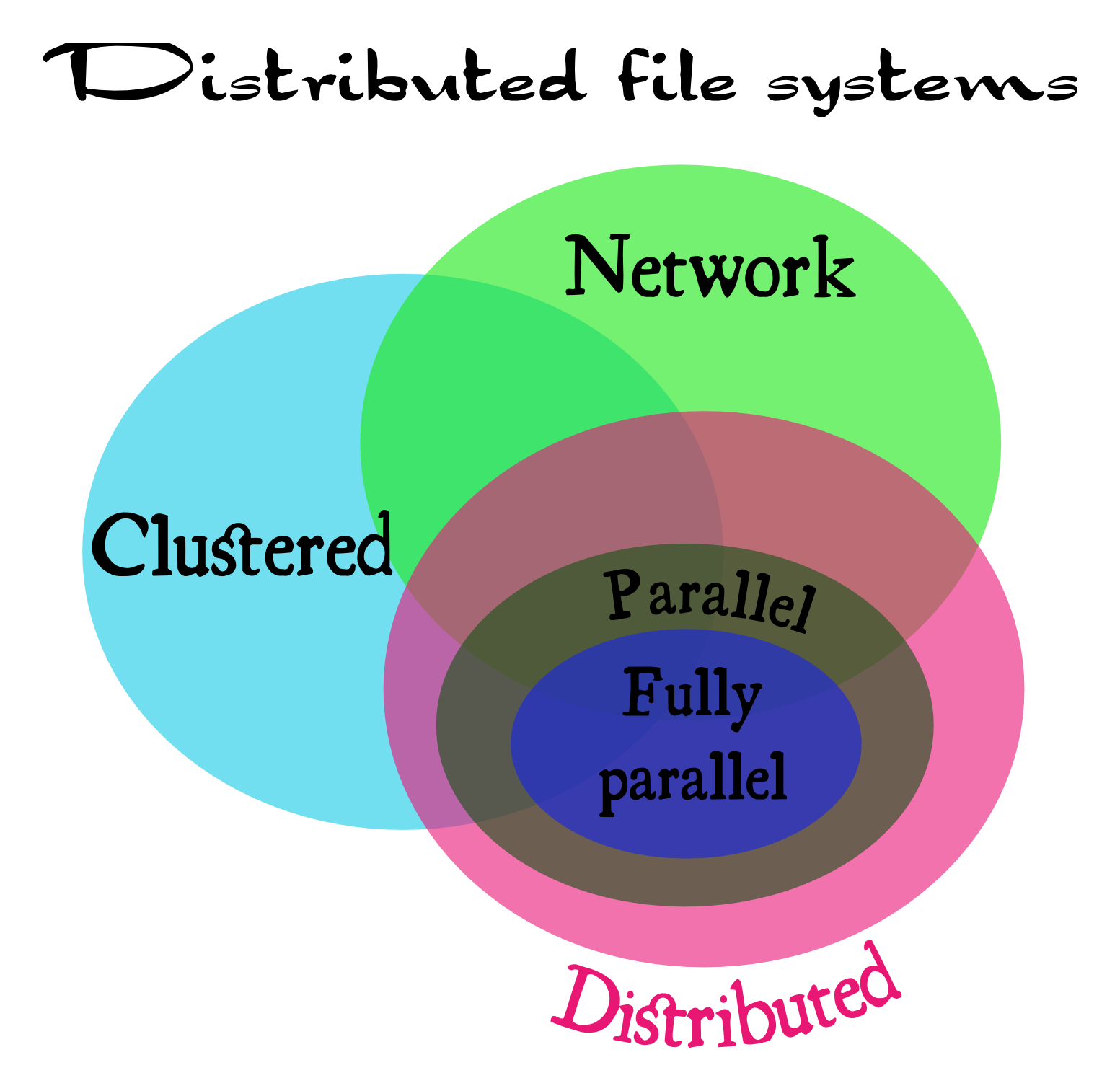
Network file systems
Network file system usually means one with a single server (or at least an appearance of a single server) and several remotely connected clients. Classical NFS3 is a good example (but not with pNFS4 extension).
Clustered file systems
Clustered file system is a file system simultaneously mounted on several local servers sharing the same data storage on a block level (usually the SAN5 model is used). These kind of setups is called shared disk file systems often. Well known examples are OCFS26 and GFS27 file systems.
Distributed file systems
Distributed (in the narrow sense) file systems are setups with multiple data servers sharing nothing between them, for each active server its own data storage is private to it. This systems usually are not geographically distributed and are local in their location due to demands of high performance interconnect (e.g. pNFS3 extension of NFS2 falls here). But there are solutions present for geographically distributed systems, even for setups distributed across different continents. Andrew File System (AFS8) is a good and widely used example.
Parallel file systems
Whenever file system is called parallel, this means it provides a parallel access to (usually all of) its storage hosts for each of its clients. This allows to avoid a bottleneck of a single host in terms of both network and I/O bandwidth, latency; CPU and cache limitations. These file systems are usually used in the High Performance Computing (HPC29) and high-end business applications like stock exchange information systems. Prominent open source examples are Lustre10, OrangeFS11 and Ceph12.
Fully parallel file systems
Parallel file systems are fully parallel when not only data, but metadata is also distributed on multiple servers accessible in parallel by clients. This is quite important for high-end performance as single metadata server will eventually become a bottleneck, especially when dealing with large directories. For example, OrangeFS11 and Ceph12 are fully parallel distributed file systems, but pNFS4 ad Lustre10 are not.
Highly Available (HA) solutions
Each class described above may contain an HA solution. Usually this is done by either a data replication (as in Ceph12) or by a disk level redundancy (RAID5/6) together with a server level redundancy (heartbeat/pacemaker) as in Lustre10 or OrangeFS11.
MPI support
If you’re working in the HPC9 field, you’ll be definitely interested in the MPI13 I/O support. ROMIO14 implements just that and is supported by many file systems, e.g. NFS3, Lustre10, OrangeFS11.
Setup considerations
Final choise should be made based on targeted applications for your setup:
- is POSIX compliance setup required? Especially POSIX file locking, it hinders greatly distributed file system performance (and is not available on many file systems at all), but may be required by some applications;
- is MPI13 needed?
- is HA needed?
- what kind of locality are you targeted on?
- are your data servers exclusive for your storage tasks?
- are you working in trusted environment?
- and many more…
Optimize your software:
- prefer a small number of large files over a large number of small files, as large directories hinder metadata servers greatly;
- prefer large data chunks over a large number of small network packets — they hinder TCP/IP stack greatly.
OrangeFS experience
At our university we selected OrangeFS because of the following:
- parallel distributed FS with good MPI support;
- reasonable performance on large directories;
- optional HA support;
- low CPU load;
- high network I/O performance (limited only by physical 1 Gbit/s bandwidth);
- native InfiniBand15 support.
Though, high performance means non full POSIX compliance, so:
- no hardlinks;
- no special files;
- no unlink(): if file is gone, then it is gone immediately and forever.
- OrangeFS should not be used for $HOME.
Setup hints:
- use as many data and metadata servers as possible;
- use large stip_size, 1 MB is a good idea to start with;
- TroveSync may be disabled to improve speed at the cost of possible data loss when server dies;
- on ethernet use jumbo frames.
This software is a good example of how ordinary user sends patches made due to daily needs and became a project contributor :)
Summary
There is no perfect distributed filesystem: to achieve the best in one aspect some others must be sacrificed. But if you understand your workload, you’ll be able to pick up a few solutions, study them to your best and have fun!
In my humble opinion the most interesting and promising solutions for their fields are: Lustre10, OrangeFS11, Ceph12 and pNFS4.
P.S. Always send your patches!
References
1 http://en.wikipedia.org/wiki/List_of_file_systems
5 http://en.wikipedia.org/wiki/Storage_area_network
6 https://oss.oracle.com/projects/ocfs2/
7 https://access.redhat.com/knowledge/docs/en-US/Red_Hat_Enterprise_Linux/6/html/Global_File_System_2/ch-overview-GFS2.html
9 http://en.wikipedia.org/wiki/Supercomputer
13 http://en.wikipedia.org/wiki/Message_Passing_Interface
Abstract licensed under Creative Commons Attribution-ShareAlike 3.0 license
Назад



























