Технология прозрачного сжатия графической памяти GPU
LVEE 2016
Каждый год анонсируются новые, все более совершенные гаджеты, использующие ядро Linux и открытые платформы: планшеты, смартфоны, телевизионные приставки, умные часы. Большинство из них оснащается мобильными GPU, используемыми для аппаратного ускорения 3D графики (OpenGL ES) и параллельных вычислений (OpenCL, RenderScript). Наиболее часто встречаются графические процессоры Mali, Adreno и PowerVR. В отличие от GPU, используемых в настольных системах, мобильные GPU не имеют встроенной памяти, а используют часть оперативной (рис. 1), предоставляемой ядром ОС — такая память становится недоступной ядру ОС и пользовательским программам. Будем называть память, используемую GPU, графической памятью. Оптимизация расхода такой памяти позволит достичь снижения цены устройств или повысить производительность за счет улучшения кешируемости приложений.
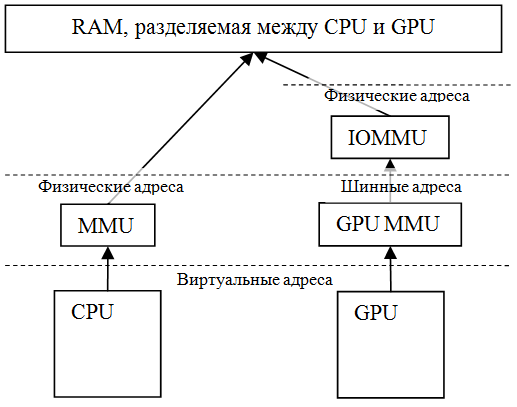
Рис. 1 — Разделение памяти между CPU и GPU
К графической памяти можно отнести GEM буферы, используемые для хранения результата рендеринга, и вспомогательные регионы (native буферы), хранящие цветовые буферы, поверхности, текстуры, различную вспомогательную информацию, относящуюся к элементам графической сцены.
Задача оптимизации использования графической памяти уже рассматривалась ранее 1, в статье упоминалась технология сжатия GEM буферов на стороне пользователя, также были отмечены высокие накладные расходы этого решения.
В настоящей работе рассматривается исключительно вопрос оптимизации использования native буферов, поскольку современные композитные менеджеры уже способны эффективно управлять GEM буферами и дальнейшая работа в этом направлении не требуется.
Авторами было проведено исследование вопроса на примере GPU Mali серий Midgard и Utgard: за счет доработки драйверов ядра удалось реализовать прозрачную компрессию редко используемых native буферов графической памяти. В результате получилось добиться экономии более 100 Мб. оперативной памяти за счет высокого коэффициента сжатия графических буферов (6-9 раз), а также наличия множества регионов графической памяти, заполненных нулями.
По своей сути решение реализует механизм схожий с подкачкой страниц (swap), при этом есть ряд особенностей, характерных для графической памяти и мобильных устройств. Ранее подобный подход рассматривался как трудно реализуемый 2.
Для сжатия некоторого региона графической памяти нужна гарантия, что он не будет использоваться CPU или GPU в процессе компрессии. Это гарантируется путем запрета доступа к страницам данного региона в таблицах страниц GPU, а также снятия отображений региона в адресные пространства процессов на CPU. После того, как соответствующие записи PTE и ATE (записи таблиц страниц CPU и GPU, соответственно) изменены, любое обращение к соответствующим адресам памяти должно вызвать исключение страничной адресации, известное как page fault или data abort.
После того как гарантировано отсутствие доступа к региону памяти, данные со страниц этого региона могут быть сжаты, а страницы освобождены. Для хранения сжатых данных графической памяти в работе применена подсистема GMC (graphical memory compression), созданная в качестве обобщенного слоя для разных драйверов GPU. GMC осуществляет управление буферами для хранения сжатых данных через подсистему ядра zpool (zsmalloc allocator 3), сжатие данных с использованием crypto comp API, управление идентификаторами сжатых страниц, а также контролирует когерентность кешей. Страницы, данные которых плохо сжимаются, не принимаются для хранения и не освобождаются. Страницы, заполненные нулями, учитываются GMC и освобождаются.
При обращении к адресам страниц графической памяти, освобожденной ранее, генерируются исключения страничной адресации. Соответствующие данные извлекаются из хранилища GMC на вновь выделенные страницы физической памяти. Осуществляется отображение новых страниц по требуемым виртуальным адресам путем изменения записей PTE или ATE в соответствующих таблицах страниц.
Кроме уже описанного механизма важным является вопрос о ранжировании регионов графической памяти по признаку частоты доступа. Сжатие активно используемой памяти может привести к катастрофическому падению производительности за счет частых исключений страничной адресации. Для решения указанной проблемы используется информация о состоянии приложений. Специальный демон (resource daemon) следит за приложениями и информирует ядро о тех из них, которые переходят в фоновый режим (становятся невидимыми на экране). Графическая память таких приложений подлежит сжатию.
Взаимодействие всех компонент во время компрессии отражено на рис. 2. Основные шаги пронумерованы.
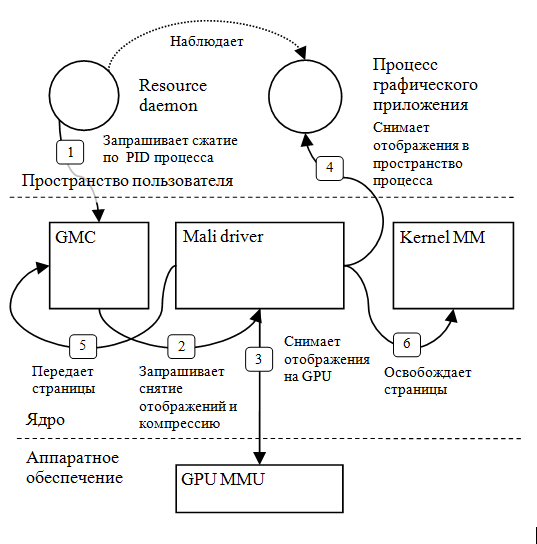
Рис. 2 — Взаимодействие компонент системы
Рис. 3 иллюстрирует снятие отображений, компрессию и освобождение страниц с позиции данных, а не потока управления и дополняет рис. 2.
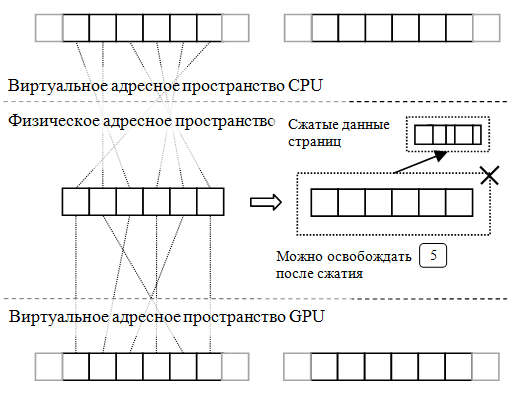
Рис. 3 — Снятие отображений и компрессия
Тестирование решения на платформах Android и Tizen показало сокращение используемой памяти — более 100 мегабайт может быть освобождено при стандартном использовании устройства, когда в фоне оказывается достаточное количество кешированных приложений. Замечено большое количество регионов, заполненных нулями, а максимальная степень сжатия данных графических буферов составила 89%. Накладные расходы, вносимые решением минимальны, а пиковые не превышают 18% (Kindle App, Google Maps). В определенных ситуациях переключение между приложениями ускоряется до 40% за счет большего количества свободной памяти, а следовательно, лучшей кешируемости приложений.
Исходный код подсистемы GMC планируется опубликовать в LKML, а изменения в драйверах Mali через группы поддержки ARM.
1 Kwon, S., Kim, S.-H., Kim, J.-S., and Jeong, J. Managing gpu buffers for caching more apps in mobile systems. Proceeding EMSOFT ’15, 207–216 (2015)
2 Carmack, J. GPU data paging, http://media.armadilloaerospace.com/misc/gpuDataPaging.htm (2010)
3 Corbet J. The ZsmallocAllocator. Linux Weekly News (2012)
Abstract licensed under Creative Commons Attribution-ShareAlike 3.0 license
Назад



























