Разработка мониторинга для тысячи хостов на основе nagios
Николай Маржан, Киев, Украина, PortaOne Inc., delgod@delgod.com
В докладе представлен опыт создания системы мониторинга для тысячи хостов. Сформулированы требования к таким системам, обсуждается степень необходимости конкретных функций. Описана архитектура и другие ключевые моменты реализации.
1. Предпосылки для создания системы
1.1. Исходные требования
В качестве исходных требований, определяющих рамки рассматриваемого подхода к мониторингу, можно назвать следующие:
- Планируемое количество хостов – 1000 и более.
- Устойчивость системы мониторинга к сбоям. Сбой на абсолютно любом уровне должен привести к уведомлению инженера в течение 3-х минут.
- Поддержка мониторинга хостов, находящихся за NAT/PAT. Без возможности проверить доступность хоста, который находится за NAT/PAT, тяжело реализовать устойчивость к сбоям.
- Устойчивость системы мониторинга к плохой связи между узлами.
1.2. Организация отдела технической поддержки
По мнению автора, следует разделить инженеров на дежурных и ведущих.
Дежурные инженеры должны покрывать график 24/7, и быть специалистами широкого профиля. Ведущие инженеры работают в обычном графике 8/5, за ними закрепляются конкретные сервера и, возможно, определенные клиенты. Ни в коем случае не следует допускать, чтобы все ведущие инженеры отвечали сразу за все сервера.
Необходимо отметить, что дежурные инженеры не всегда устраняют источник проблемы: в некоторых случаях они “лечат симптомы” (т.е. просто стабилизируют состояние). Также часто они не обращают внимания на проблемы, которые устранились сами по себе, без вмешательства.
Таким образом, добиться качественного устранения источников проблем от дежурных инженеров невозможно: на практике проблемы накатываются комом (много и сразу), нужно параллельно выполнять и другие задачи, подходит конец смены и т.д.
Потому наблюдение (и ответственность) за общим состоянием сервера (а не за конкретным случаем сбоя) следует возложить на ведущих инженеров.
1.3. Требования к визуализации
Автор считает визуализацию бичом всех систем мониторинга: это самое слабое звено в цепи “заболевание-доктор”. Универсальные требования к визуализации трудно сформулировать, они очень сильно зависят от того, как построена организационная структура отдела.
Дежурному инженеру требуется следующее:
- Список актуальных проблем. Из этого списка нужно исключить те проблемы, которыми уже кто-то занимается. Данный список не должен являться историей изменений состояний (событий).
- Когда инженер “забирает себе” проблему (начинает ею заниматься), он должен видеть полное актуальное состояние проблемного хоста тут же (не заходя на сервер).
- Видеть “историю болезни” конкретного хоста (напр.: если такая проблема повторяется не первый раз, что делали другие инженеры в этой ситуации, какие диагностические процедуры посоветовал провести ведущий инженер в случае повторения и т.д.).
- Записывать информацию о проведенных процедурах в “историю болезни”.
Ведущему инженеру нужно следующее:
- Возможность получения отчета об изменении состояний и о проведенных процедурах.
- История состояний в динамике (графики).
- Возможность записи в “историю болезни” информации о проведенных процедурах; возможность предписывать диагностические процедуры, которые следует выполнить при повторении сбоя, и т.д.
1.4. О функциях системы мониторинга
Перечислим возможные функции мониторинга на конечном хосте:
- Сбор информации о текущем состоянии.
- Построение графиков.
- Принятие решений о текущем состоянии на основании собранной информации.
- Выполнение определенных действий на основании собранной информации.
Принятие решений о состоянии. Например, есть нагрузка на HDD (в процентах). Вопрос: Где принимать решение о том, является ли текущее состояние критическим? Если на центральном сервере – этим очень удобно централизованно управлять. Но о состоянии некоторых сервисов можно судить, только проверив около десятка специфических параметров, которые не всегда можно выразить в числах. Поэтому решение о текущем состоянии принимает конечный хост.
Выполнение определенных действий. Предположим, что на этом сервере должен быть всегда запущен сервис httpd. Сервис может быть остановлен по двум причинам. Первая – его специально остановили для обслуживания. Вторая – он самопроизвольно “упал”. Но мониторинг практически невозможно научить понимать причину остановки.
Система мониторинга должна запустить сервис, если он остановлен, в одном из трех случаев:
- Вы не разработчик software, и не можете исправить или даже диагностировать причину самопроизвольного падения.
- Стоимость диагностики или исправления причины падения неоправданно велика.
- Нет поддержки 24/7.
Однако, с другой стороны, существуют и веские причины не производить запуск. В частности, всегда предпочтительно разобраться в причине падения и устранить ее. Иначе при проведении обслуживания, если не выключить мониторинг, он может привести систему в неожиданное состояние. Также иногда мониторинг может усугубить сбой своими попытками его исправить.
2. Реализация
После исследования существующих OpenSource-решений для мониторинга, в качестве основы был выбран проект nagios с использованием транспорта nagios nsca. Только это решение позволяло добиться нужного уровня надежности.
2.1. Архитектура
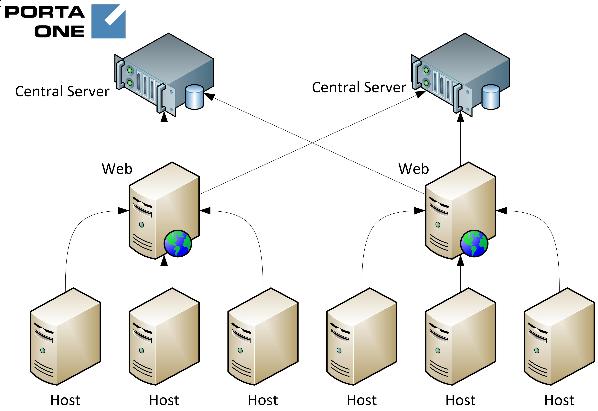
Рис. 1 – Архитектура
На рисунке 1 выделим следующие основные элементы архитектуры: конечный хост; хост в режиме Web; центральный сервер.
Сервера разбиваются на группы по 1-100 хостов в каждой. Сервера в одной группе должны быть физически размещены рядом. Хорошо, если сервера можно разделить логически (например, по клиентам). Часто есть компания, в интересах которой проводится мониторинг (конечный владелец или арендатор серверов). Иногда такая компания имеет свой штат инженеров, которые хотят иметь централизованный доступ к мониторингу. Потому в каждой группе выбирается 1 сервер, на котором установлен (или будет установлен) сервис http. На этом сервере будет настроен Web-интерфейс nagios, на нем будут собираться графики.
Все хосты в группе должны отсылать результаты своих проверок исключительно на хост в режиме Web. Хост в режиме Web не опрашивает сервера, он пассивно принимает результаты мониторинга. Но основная функция хоста в режиме Web – это снижение нагрузки на центральный сервер. Хост в режиме Web должен отсылать сообщения на центральный сервер, не по одному (как это делают конечные хосты), а по 20 сообщений за одну транзакцию.
Центральный сервер не опрашивает сервера, он пассивно принимает результаты мониторинга. Центральный сервер принимает сообщения со всех серверов и отображает согласно требованиям к визуализации, а также генерирует отчеты.
2.2. Полный перечень используемого ПО
Конечный хост:
- Nagios Official plugins. http://nagiosplugins.org
- Плагины собственной разработки (порядка 2000 строк perl-кода).
- Nagios. http://nagios.org
- Генератор конфигурационных файлов nagios собственной разработки (порядка 300 строк perl-кода).
- Nagios NSCA client. http://nagios.org/download/addons
Хост в режиме Web:
- Nagios Official plugins. http://nagiosplugins.org
- Плагины собственной разработки (порядка 2000 строк perl-кода).
- Nagios. http://nagios.org
- Генератор конфигурационных файлов nagios собственной разработки (порядка 300 строк perl-кода).
- Nagios NSCA server and client. http://nagios.org/download/addons
- PNP4Nagios. http://www.pnp4nagios.org
Центральный сервер:
- Nagios. http://nagios.org
- Генератор конфигурационных файлов nagios собственной разработки (порядка 300 строк perl-кода).
- Nagios NSCA server. http://nagios.org/download/addons
- Nagios NDOUtils. http://nagios.org/download/addons
- MySQL server. http://www.mysql.com
- Web интерфейс собственной разработки.
2.3. Надежность

Рис. 2 – Этапы обработки и пересылки сообщения
Как видно из рисунка 2, результат проверки (сообщение) проходит множество этапов обработки и пересылки, перед тем как попасть на центральный сервер. На любом из этих этапов может случиться сбой, от которого нельзя застраховаться и который трудно диагностировать.
Решение этой проблемы простое:
- Центральный сервер всегда знает о списке сервисов, которые должны отслеживаться на конечном хосте.
- Каждый сервис проверяется 1 раз в минуту, сообщение всегда отсылается на центральный сервер.
- Nagios на центральном сервере настроен так, что автоматически генерирует критическое состояние для сервиса, если прошло более 3 минут с момента получения последнего сообщения.
Такой подход обеспечивает страховку от абсолютно любого сбоя при транспортировке, а так же обеспечивает централизованный доступ к актуальным данным.
2.4. Автоматическая генерация конфигурационных файлов
При попытке внедрения прототипа системы возникла проблема: создание конфигурационных файлов nagios вручную (с использованием шаблонов) занимает много времени, и вдобавок приводит к недопустимому проценту ошибочного конфигурирования младшими инженерами.
Потому было принято решение о создании инструмента, который бы автоматически генерировал конфигурационные файлы nagios.
Функции генератора конфигурационных файлов:
- Анализ конфигурации программного обеспечения хоста, включение нужных проверок.
- Определение адресата для отсылки результатов проверок.
- Включение Web-режима, включение приемки результатов с других хостов, создание графиков.
- Функционирование в автоматическом режиме (без участия инженера).
Вмешательство человека нужно только для обновления системы мониторинга и в случае изменения пороговых значений для критических состояний.
3. Выводы
Система мониторинга, построенная на описанном подходе, находится в промышленной эксплуатации около 2 лет. Фактическое количество хостов около 700. Текущая нагрузка на центральные сервера (с процессорами Core 2 Duo, ОЗУ 4Гб, LA 0.5, idle 70-90%, 1.5Гб использованной памяти, swap 0Мб) – незначительная. Было своевременно отмечено, что каждая организация имеет свою систему оказания технической поддержки, а от этого очень сильно зависят потребности в визуализации. Как следствие, был разработан удобный интерфейс, построенный по принципу “от потребителя”. Эта система обладает большой устойчивостью к плохому сетевому соединению и высоким уровнем надежности. Благодаря исключению человека из процесса конфигурирования, система имеет повышенный иммунитет к человеческому фактору.
Материалы к докладу
- Презентация:
 Просмотреть Загрузить
Просмотреть Загрузить




























