Применение нереляционных БД при построении высоконагруженных масштабируемых систем
Илья Бакулин, Москва, Россия, Deglitch Networks, ilya@deglitch.com
В докладе рассмотрено применение нереляционных баз данных для решения проблем масштабируемости веб-приложений. Рассмотрена модель данных одной из популярных систем хранения такого типа – Cassandra 1. Приведены отличия Cassanrda от других решений. Также показаны возможные способы трансформации традиционных реляционных схем представления данных в схему Cassandra, в частности – как это планируем сделать мы в SMS Traffic. Наконец, рассмотрены недостатки и ограничения как нереляционных БД в целом, так и Cassandra в частности.
По мере возрастания популярности каждое веб-приложение рано или поздно сталкивается с проблемами производительности. Эти проблемы имеют разные корни и могут быть связаны как с неверно спроектированной архитектурой самого приложения, так и с внешними ограничениями. В роли последних могут выступать, например, недостаточные мощности Application-серверов либо серверов БД, неоптимальная структура базы данных. Первая проблема решается добавлением серверов в кластер, а вот решение второй связано с оптимизацией схемы хранения данных, переписыванием кода, разбиением сложных запросов и тд. Но что делать, если, несмотря на то, что все запросы уже используют индексы и упрощать их дальше становится всё сложнее, приложение всё равно испытывает проблемы с доступом к данным в БД?
Как один из вариантов решения проблемы масштабирования можно рассмотреть системы хранения, использующие более простую модель хранения данных, нежели традиционная реляционная модель. Один из проектов, использующих нереляционную схему хранения – Cassandra, был разработан в недрах компании Facebook, открывшей его исходные тексты в 2008-м году. В настоящее время Cassandra-кластер в Facebook состоит более чем из 600 машин, а объём хранимых данных – более 120 ТБ. Также о своём переходе на Cassandra заявили такие проекты, как Twitter 2, Digg 3 и Reddit 4.
Главное отличие Cassandra от остальных популярных NOSQL-решений кроется в используемой модели данных. NOSQL-хранилища дают возможность работать с ключами либо со списками ключей, различаясь поддерживаемыми типами данных, уровнями изоляции доступа и удобством интерфейсов доступа к данным. В Cassandra используется более сложная структура, которую можно представить как 4-х либо 5-уровневый хеш. Верхний уровень иерархии – KeySpace (в RDBMS ближайший аналог – база данных). Далее следует
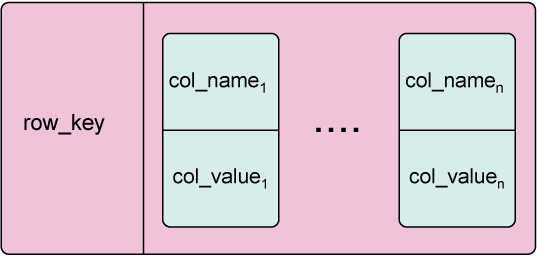
Рис. 1 – Column Family
Индекс “ряда” в этой таблице имеет особое значение – на его основе выбирается место хранения блока данных среди машин кластера. Обратившись по ключу, можно выбрать семейство колонок, представляющих собой триплет “имя-значение-временная_отметка”. Примечательно, что количество триплетов, хранимых в разных “рядах”, может отличаться в десятки и сотни раз!
Наконец, вместо ColumnFamily может быть сохранён SuperColumnFamily.
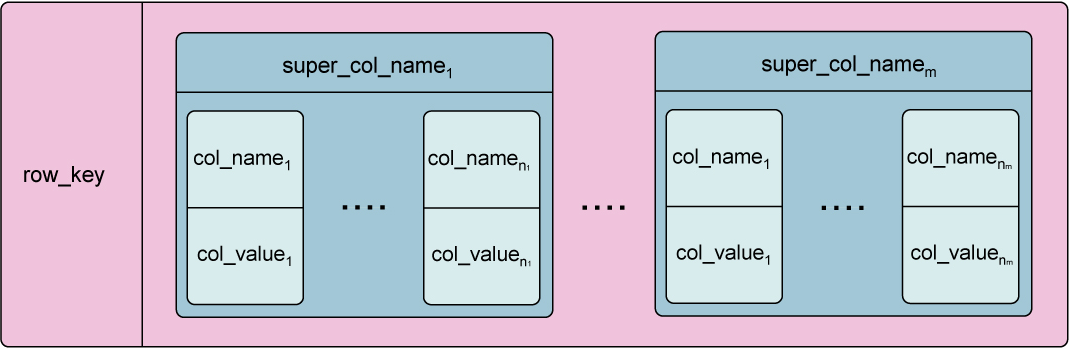
Рис. 2 – SuperColumnFamily
Элементами, хранимыми в каждом “ряду” из SuperColumnFamily, будут уже не просто триплеты, а SuperColumns, каждая из которых содержит неограниченное количество триплетов-колонок.
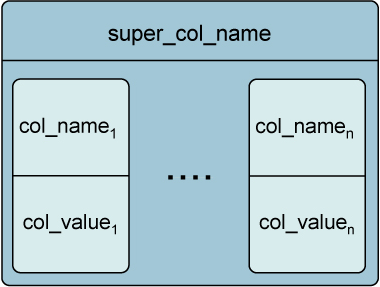
Рис. 3 – SuperColumn
“Из коробки” Cassandra поддерживает несколько схем распределения данных по узлам кластера, умеет учитывать географическое расположение серверов в целях минимизации передаваемого по сети трафика, и при добавлении новых узлов в кластер автоматически происходит разгрузка наиболее загруженных узлов. При необходимости распределение данных по машинам может быть изменено вручную.
Для приложений при чтении и записи можно выбирать различный уровень консистентности данных – например, можно попросить Кассандру работать как в полностью асинхронном режиме (в этом случае запрос на запись данных будет мгновенно возвращать управление в программу), так и дожидаться записи на всех репликах или чтения со всех реплик.
Расплачиваться за мощную распределённую систему, храняющую неограниченный объём данных, приходится отсутствием привычных по RDBMS средств работы и анализа данных. Cassandra не поддерживает сложных индексов и, соответственно, сложных запросов, работа с предложенной схемой предполагает активную денормализацию данных, ручное конструирование индексов и необходимость самостоятельно следить за целостностью данных. Однако при правильном использовании и при наличии ежедневно возрастающего количества успешных внедрений переход на Cassandra может дать возможность построения действительно хорошо масштабируемого приложения, мгновенно оперирующего гигантскими наборами данных.
Ссылки:
1 The Apache Cassandra Project
2 Cassandra @ Twitter: An Interview with Ryan King
3 Looking to the future with Cassandra
4 Reddit’s now running on Cassandra
Изображения: Cassandra’s data model cheat sheet
Материалы к докладу
- Презентация:
 Просмотреть Загрузить
Просмотреть Загрузить - Видео: Загрузить




























