Flume и Morphlines -- трансформация потоков данных без строчки кода.
LVEE 2014
Введение
Одним из столпов на которых стоят *nix системы является концепция “конвейеров” (pipeline) для обеспечения совместной работы множества программ. К сожалению возможности конвееров, без использования вспомогательных средств вроде netcat, ограничиваются пределами одного хоста и слабой параллелизацией данных. Даже классические задачи, например, сбор и обработка большого количества логов с фермы серверов становится головной болью администратора.
В то же время адепты Big Data активно развивают концепцию DataFlow, которая по сути является развитием все той же концепции конвейеров, но предназначена для организации управления большими потоками данных.
Apache Flume1

Flume — это рапределенный, надежный сервис для эффективного сбора, агрегирования и передачи больших потоков данных. Простой и гибкий в настройке, Flume обладает очень архитектурой, позволяющей настроить буквально любой аспект поведения сервиса. Используется простая и легко расширяемая модель данных, что очень удобно для использования в аналитических сервисах.
Каждый агент Flume состоит из 3 составляющих:
- source — источник данных, фактически сервис умеющий преобразовывать входные данные во внутреннее представление;
- channel — очередь сообщений, служащий связующим звеном между источником данных и выходом;
- sink — сервис умеющий преобразовать внутреннее представление данных в необходимое для потребителя.
Особую пикантность придает то, что помимо множества уже существующих “стандартных” компонентов, существует возможность легкого создания и использования любой из составляющих агента.
Каждая составляющая агента может состоять из одного или более компонентов, что превращает Flume в конструктор с возможностью построения любой топологии по передаче потоков данных.
Базовые блоки “конструктора”
На данный момент существует несколько десятков стандартных компонентов и с каждым релизом их становится все больше:
- Source — начиная от запуска любой утилиты, дающей вывод через stdout и заканчивая организацией полноценного сетевого сервиса, работающего с различными сетевыми протоколами: tcp, http, syslog, AVRO, Thrift и др.;
- Memory Channel — как in-memory, для скорости, так и надежная очередь с записью промежуточных данных в файл или даже базу данных;
- Sink — от банальной записи в файл (организация логов) на локальной или кластерной файловой системе, до интеграции с другими агентами Flume или BigData системами.
Синтаксис файла конфигурации, описывающего агента очень прост и приспособлен для использования человеком:
# properties for sources <Agent>.sources.<Source>.<someProperty> = <someValue> # properties for channels <Agent>.channel.<Channel>.<someProperty> = <someValue> # properties for sinks <Agent>.sources.<Sink>.<someProperty> = <someValue>
Топология
Возможность агентов Flume взаимодействовать между собой позволяет создать действительно распределенную и, при необходимости, надежную сеть передачи потоков данных.
Так, например, с помощью Avro Sink и Avro Source очень легко реализовать агрегирование из нескольких источников в одну систему (топология “fan-in”):
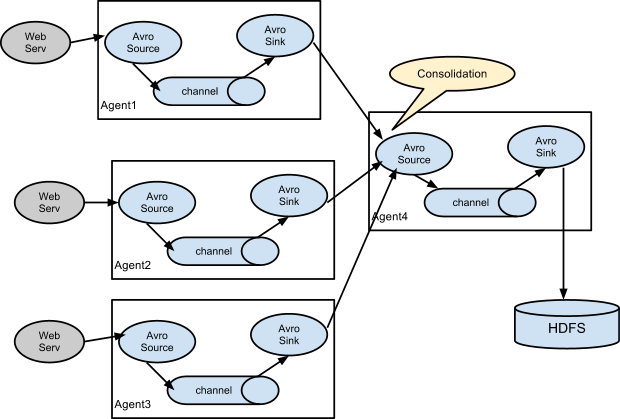
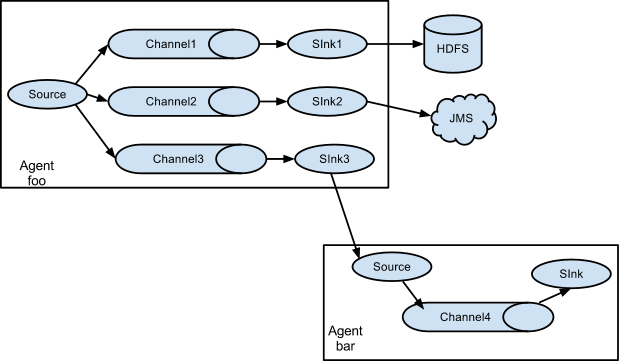
Завязав несколько Sink на одну очередь можно легко добиться дробления одного потока данных на несколько более мелких (топология “fan-out”).
А при использовании нескольких очередей можно добиться мультиплексирования (роутинга) отдельных записей “по условию”, как это сделано в системах очередей сообщений:
Чудесное превращение Flume в ETL
ETL2 (от англ. Extract, Transform, Load — дословно «извлечение, преобразование, загрузка») — один из основных процессов в управлении хранилищами данных, который включает в себя:
- извлечение данных из внешних источников;
- их трансформация и очистка, чтобы они соответствовали нуждам бизнес-модели;
- и загрузка их в хранилище данных.
Если с Extract и Load у Flume все очевидно, то для Transform у Flume существует замечательный и мощнейщий механизм под названием “Interceptor”, который позволяет производить преобразование данных в пределах каждой записи.
Как и для других элементов, для “Interceptor” существует несколько базовых механизмов, среди которых особняком стоит механизм Morphlines, позволяющий преобразовывать данные без строчки кода!
Morphlines3
Morphlines — это фреймфорк с открытым исходным кодом, разработанный как часть системы Cloudera Search. Основная цель создания Morphlines — быстрая разработка приложений для обработки потоков данных в Hadoop с последующей записью результатов в Apache Solr, HBase, HDFS и прочие системы.
В лучших традициях “правила разделения” приведенным Эриком Реймондом в его бессмертной книге “Искусство программирования в UNIX”, в Morphlines была заложена концепция управления с помощью данных — фактически конфигурационного файла, описывающего pipeline последовательных преобразований для записи данных:

Фреймворк получился настолько удачным, что он был выделен в отдельную часть, а также предусмотрены механизмы для встраивания в любое приложение написанное на Java.
Модель данных.
Концепция Morphlines предполагает, что данные поступают в виде бесконечного (или хотя бы достаточно большого) потока записей.
Центральной частью Morphlines является запись (Record), которая представляет собой набор именованных полей, причем каждое поле может содержать от одного и более значений. Поля записи могут использоваться как key-value пары, так и выстраиваться в более сложные связи. Для упрощения можно рассматривать работу с записью, как работу с JSON-объектом, поскольку поддерживаются все возможности по организации данных, которые предоставляются этой нотацией.
На самом деле все еще более интересно, поскольку в качестве значения для поля можно использовать любой объект Java.
Конфигурационный файл
Конфигурационный файл представляет собой последовательный список команд для преобразования данных, описанный в формате HOCON (Human Optimized Config Object Notation), кроме того предоставляются возможности бранчевания с помощью команд pipe, if и tryRules.
Список возможных команд преобразования чрезвычайно обширен4, но не ограничивается только предопределенными командами — достаточно легко можно написать свою реализацию недостающего функционала. Более того, с помощью команды “java” можно встраивать исходный код прямо в конфигурационный файл!
Чрезвычайно мощным инструментом является команда “grok” реализующая разбор любой текстовой строки с помощью регулярных выражений с использованием одноименного синтаксиса из пакета LogStash5. Особенно приятно то, что для отладки можно использовать онлайн дебаггер “Grok Debugger”6.
Синтетический пример
Disclaimer: поскольку работающая система прикрыта завесой NDA, для примера был взят первый попавшийся работающий сервис — ftp-сервер “vsftpd”.
В качестве примера разработаем систему, собирающую статистику скачивания файлов со множества ftp-серверов и сохраняющую ее в файл в формате JSON, с указанием времени скачивания (в unix-time), имени файла, ip-адреса клиента, а так же, в качестве бонуса, имени сервера с которого скачали этот файл.
В логе vsftpd данная строка выглядит следующим образом:
Tue Jul 22 19:15:23 2014 [pid 9388] [vsftpd] OK DOWNLOAD: Client "10.6.136.54", "/video/HighLoad master-class/out-1406031869.mkv", 189505527 bytes, 3909.30Kbyte/sec
Конфигурационный файл для Flume
В примере описаны два агента:
- vsftpd — для парсинга логов и отсылки данных на центральный сервер
- collector — принимает данные от ftp серверов и складывает в файлы
### Agent working on vsftpd node vsftpd.sources = logreader vsftpd.channels = mem-channel vsftpd.sinks = avro-out # default memory channel vsftpd.channels.mem-channel.type = memory # Read from log file vsftpd.sources.logreader.type = exec vsftpd.sources.logreader.command = tail -F /var/log/vsftpd.log vsftpd.sources.logreader.channels = mem-channel # expecting veeeeery loooong string vsftpd.sources.logreader.deserializer = LINE vsftpd.sources.logreader.deserializer.maxLineLength = 32768 # set interceptor for converting string to AVRO vsftpd.sources.logreader.interceptors = morphline # morphline interceptor config vsftpd.sources.logreader.interceptors.morphline.type = org.apache.flume.sink.solr.morphline.MorphlineInterceptor$Builder vsftpd.sources.logreader.interceptors.morphline.morphlineFile = /tmp/flume/conf/morphlines.conf vsftpd.sources.logreader.interceptors.morphline.morphlineId = vsftpFileLog # sink stream over avro channel vsftpd.sinks.avro-out.type = avro vsftpd.sinks.avro-out.channel = mem-channel vsftpd.sinks.avro-out.hostname = 127.0.0.1 vsftpd.sinks.avro-out.port = 5555 ### Logs collector agent collector.sources = avro-in collector.channels = mem-channel collector.sinks = file-out # get stream over avro channel collector.sources.avro-in.type = avro collector.sources.avro-in.channels = mem-channel collector.sources.avro-in.bind = 0.0.0.0 collector.sources.avro-in.port = 5555 # default memory channel collector.channels.mem-channel.type = memory # write stream to file every 5 minutes or 1000 events collector.sinks.file-out.type = file_roll collector.sinks.file-out.sink.rollInterval = 300 collector.sinks.file-out.batchSize = 1000 collector.sinks.file-out.sink.directory = /tmp/flume/log/ collector.sinks.file-out.channel = mem-channel
Для оптимизации необходимо “поиграться” с настройками, особенно каналов. Также необходимо проверить пути в конфигурационном файле и адаптировать их к своей системе.
Файл преобразований Morphlines
Описание преобразований находится в комментариях к каждой из команд Morphlines.
morphlines: [
{
id: vsftpFileLog
importCommands: [ "org.kitesdk.**" ]
commands: [
{ readLine { charset : UTF-8 } }
# Parse input string and extract fields:
# timestamp, ip, file, size
{ grok {
dictionaryFiles : [ /tmp/flume/conf/grok ]
dictionaryString : """
TS %{DAY} %{MONTH} %{MONTHDAY} %{TIME} %{YEAR}
PATH (?>/(?>[\w\s_%!$@:.,-]+|\\.)*)+
"""
expressions : {
message : """%{TS:timestamp}.*Client "%{IP:ip}", "%{PATH:file}", %{INT:size}.*"""
}
} }
# Convert input time from custom to Unixtime format
{ convertTimestamp {
field : timestamp
inputFormats : [ "EEE MMM dd HH:mm:ss yyyy" ]
outputFormat : "unixTimeInSeconds"
} }
# Add name of host to field "server"
{ addLocalHost {
field : server
useIP : false
} }
# Convert Morphline Record to AVRO-event according schema
{ toAvro {
schemaString : """
{ "type": "record",
"name": "ftpfile",
"fields": [
{ "name": "timestamp", "type": "long", "default": -1 },
{ "name": "server", "type": "string", "default": "" },
{ "name": "ip", "type": "string", "default": "" },
{ "name": "file", "type": "string", "default": "" },
{ "name": "size", "type": "long", "default": -1 }
]}
"""
} }
# serialize the object
{ writeAvroToByteArray: {
format: containerlessJSON
} }
]
}
]
Запуск
Монитор лог-файлов сервера:
flume-ng agent -n vsftpd -f /tmp/flume/conf/flume.properties -C "/usr/lib/kite/*:/usr/lib/kite/lib/*"
И “сервер” занимающийся сбором статистики и записью в файлы:
flume-ng agent -n collector -f /tmp/flume/conf/flume.properties
Краткий вывод
При совместном использовании Flume с поддержкой Morphlines можно организовать распределенную систему обработки потоковых данных почти любой сложности, буквально не написав ни строчки кода, что должно особенно понравится администраторам.
Также можно констатировать, что, не смотря на то, что оба инструмента написаны на Java, их архитектура отлично укладывается в принципы, декларируемые философией Unix, а использование близко к “классической” концепции pipeline.
1 http://flume.apache.org/FlumeUserGuide.html
2 https://ru.wikipedia.org/wiki/ETL
3 http://kitesdk.org/docs/current/kite-morphlines/index.html
4 http://kitesdk.org/docs/current/kite-morphlines/morphlinesReferenceGuide.html
5 http://logstash.net/docs/1.4.2/filters/grok
6 http://grokdebug.herokuapp.com/
Abstract licensed under Creative Commons Attribution-ShareAlike 3.0 license
Back



























